
2025. 2. 14. 13:37ㆍ읽어보기, 교재/만들면서 배우는 생성 AI
생성적 적대 신경망(Generative Adversarial Network)의 발견은 생성 모델링의 역사에서 중요한 전환점.
4.1 소개
- GAN은 생성자와 판별자라는 두 적대자 간의 싸움.
- 생성자 : 랜덤한 잡음을 원본 데이터 셋에서 생성한 것처럼 보이는 샘플로 변환.
- 판별자 : 샘플이 원본 데이터 셋에서 나왔는지, 생성자의 위조품인지 예측.
=> 둘을 번갈아가며 훈련.
4.2 심층 합성곱 GAN(DCGAN)
- 생성자의 마지막 층에서는 시그모이드보다 tanh를 사용.
=> 더 강한 그레디언트를 제공.
* 시그모이드 : (0, 1) 사이의 값을 출력.
* 하이퍼볼릭탄젠트 : (-1, 1) 사이의 값을 출력.
4.2.2 판별자
- 판별자의 목표는 이미지가 진짜인지 가짜인지 예측.
=> 지도 학습의 분류 문제.

* 마지막 합성곱 층에서 텐서의 크기는 1 X 1 X 1이므로 Dense층이 필요하지 않음.
* LeakyReLU 사용시 가중치를 부여하는데 이는 음수 값일 때의 작은 기울기 값을 의미.
x = layers.LeakyReLU(0.2)(x)
4.2.3 생성자
- 생성자의 입력은 다변량 표준 정규 분포에서 뽑은 벡터(랜덤).
- 출력은 원본 이미지와 동일한 크기의 이미지.
=> GAN의 생성자는 VAE의 디코더와 동일한 역할. - Conv2DTranspose(전치 합성곱) 층 대신 업샘플링 사용 가능.
- 업샘플링
- UpSampling2D 층 + 스트라이드 1
- 제로 패딩을 사용하지 않고 기존 픽셀 값을 업샘플링.
- Conv2DTranspose 층은 이미지 경계에 품질을 떨어트린다고 여겨지지만 여전히 많이 사용.
=> 무엇을 사용할지 테스트 필요.
4.2.4 DCGAN 훈련
- 판별자의 훈련 : 지도학습(이진 크로스 엔트로피)으로 원본 훈련 샘플과 생성자가 생성한 가짜 훈련 샘플을 훈련.
- 이진크로스 엔트로피로 생성된 이미지에 점수를 부여하고 높은 점수를 낸 이미지로 최적화.
- 생성자와 판별자를 번갈아가며 훈련.
- 생성자가 생성한 이미지가 진짜 이미지에 가까운 값으로 예측되어야 함.
- 판별자 손실 : 진짜 이미지와 가짜 이미지에 대한 이진 크로스 엔트로피의 평균.
- 생성자 손실 : 진짜 이미지와 생성된 이미지에 대한 판별자 예측 사이의 이진 크로스 엔트로피.
- 판별자와 생성자가 우위를 차지하려도 끊임 없이 경쟁해 훈련 과정 불안.
- 충분한 시간이 지나면 판별자가 우세해짐.
=> 생성자가 이미 고품질의 이미지를 생성.

* 레이블 평활화 : 훈련 레이블에 랜덤한 잡음을 소량 추가해 판별자가 풀어야 할 과제가 어려워지므로 생성자릉 과도하게 압도하지 못함.
4.2.5 DCGAN 분석
- 성공적인 모델은 훈련 세트에서 이미지를 단순히 재생성 하는것이 아님.
- 생성된 특정 샘플에서 가장 비슷한 훈련 세트 이미지를 찾아 이를 테스트 필요.
=> 이 때 사용되는 것이 L1 노름(norm).
* L1 norm : 벡터의 크기를 측정하는 방법 중 하나로 벡터의 각 성분의 절대값을 합하여 계산. 두 점간의 거리 측정 가능(주로 격자 공간).
def compare_images(img1, img2):
return np.mean(np.abs(img1 - img2))* abs(absolute value) : 절대값.
4.2.6 GAN 훈련의 팁과 트릭
- GAN은 훈련하기가 매우 어려움.
- 판별자가 생성자보다 훨씬 뛰어난 경우.
- 그래디언트가 완전히 사라져 학습이 이루어지지 않음.
- 해결책
- Dropout 값을 늘려 정보의 양을 줄임.
- 학습률을 줄임.
- 합성곱 필터 수를 줄임.
- 레이블에 잡음을 추가.
- 일부 이미지의 레이블을 무작위로 뒤집음.
- 생성자가 판별자보다 훨씬 뛰어난 경우.
- 판별자를 쉽게 속이는 방법을 찾는 ‘모드 붕괴(mode collapse)’ 가 일어남.
- 판별자를 속이는 하나의 샘플(모드)에 모든 포인트를 맵핑해 그래디언트가 0으로 붕괴.
- 유용하지 않는 손실.
- 생성자는 현재 판별자에 의해서만 평가되고 판별자는 계속 향상되기 때문에 평가된 손실들을 비교하기가 어려움.
- 위 그림[4-6]에서 볼 수 있듯 손실로만으로는 훈련 과정을 모니터링하기 어려움.
- 하이퍼파라미터
- 튜닝해야할 파라미터가 상당히 많을 뿐더러 작은 변화에도 매우 민감.
=> 위 문제들을 해결하기 위해선 와서스테인 GAN-그레디언트 페널티(WGAN-GP) 사용.
4.3 WGAN-GP
- 안정적인 GAN 훈련을 돕는 큰 발전.
4.3.1 와서스테인 손실
- GAN에서는 판별자와 생성자를 훈련하는 데 이진 크로스 엔트로피를 사용.
- GAN은 레이블을 1, 0을 사용하지만 와서스테인 손실은 1, -1 을 사용.
- 또한, 시그모니드 활성화 함수를 제거해 예측 범위가 (0, 1) 범위(확률) 에 국한 되지 않고 (-∞, ∞) 범위(점수)를 사용.
=> WGAN에서의 판별자는 보통 비평자(critic)로 불림. - 비평자는 진짜 이미지와 생성된 이미지에 대한 예측 사이의 차이를 최대화.
=> WGAN 생성자는 비평자로부터 가능한 높은 점수 받는 이미지를 생성.
4.3.2 립시츠 제약
- 신경망에서는 일반적으로 큰 숫자를 피해야함.
- 비평자가 ‘1-립시츠 연속 함수’가 되게 추가적인 제약.
- 1-립시츠 연속 함수 : 두 이미지 사이에서 비평자의 예측이 변화하는 비율 제한.(기울기의 절대값이 어디에서나 최대 1. 상승, 하강 비율을 제한.)

4.3.3 립시츠 제약 부과하기
- 원문 WGAN 논문에서는 비평자의 가중치를 작은 범위 (-0.01, 0.01) 안에 놓이도록 훈련 배치가 끝나면 가중치 클리핑(Weight Clipping)을 사용해 립시츠 제약.
=> 학습 속도 감소하고 정확한 그래디언트가 없어서 학습에 문제.
=> 와서스테인 GAN-그래디언트 페널치 사용.
4.3.4 그레디언트 페널티 손실
- 그레디언트 페널티 : 그레디언트 노름이 1에서 벗어날 경우 모델에 불이익을 주는 항으로 비판자의 손실 함수에 포함시켜 립시츠 제약 강제.
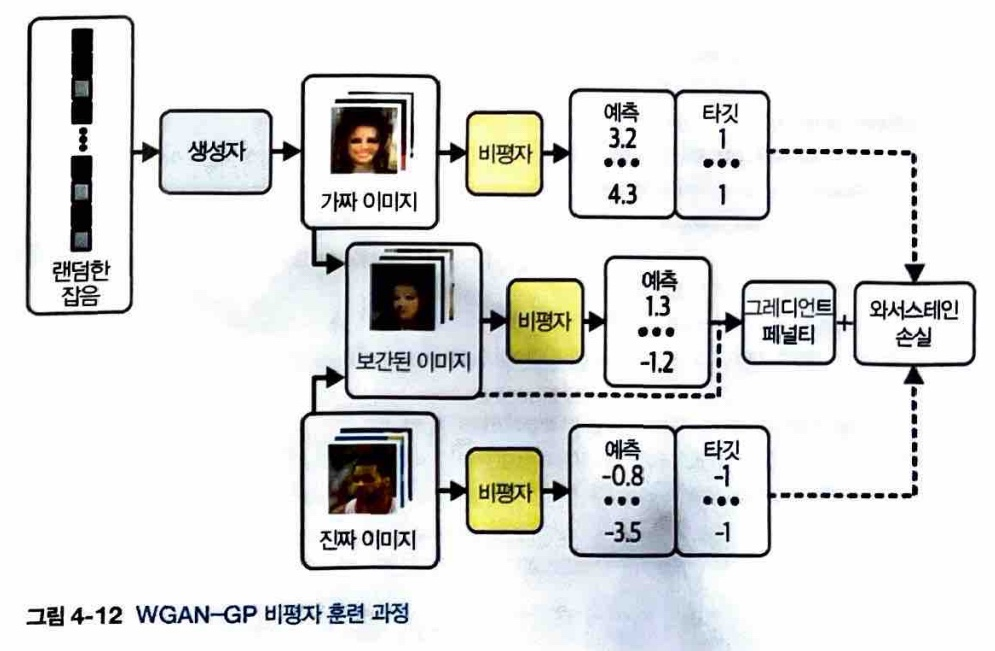
- 입력 이미지에 대한 예측의 그레디언트 노름과 1 사이의 차이를 제곱해 자연스럽게 그레디언트 페널티 항을 최소화하는 가중치를 찾음. => 립시츠 제약을 따름.
- 모든 그레디언트를 계산하기 힘들므로 일부 지점에서만 계산.
- 진짜 이미지와 가짜 이미지 쌍을 연결한 직선을 따라 무작위로 포인트를 선택해 보간(interpolation)한 이미지 사용.
* 그래디언트 노름 : 손실 함수의 기울기.
* 보간 : 통계적 또는 실험적으로 구해진 데이터를 기반으로, 주어진 변수에 대한 함수 값을 구하는 과정.
- 그래디언트 페널티 손실 함수 과정

- 배치 이미지마다 랜덤한 숫자를 생성해 벡터 alpha에 저장.
- 보간 이미지 계산.
- 비평자에게 보간 이미지 점수 요청.
- 보간 된 이미지에 예측된 그레디언트 계산.
- 이 벡터의 L2 노름을 계산.
- L2 노름과 1 사이의 평균 제곱 거리를 반환.
* L2 노름 : 벡터의 각 성분의 제곱을 합한 후 제곱근을 취한 벡터 크기 측정법(피타고라스 빗변 거리, 유클리드 거리).
4.3.5 WGAN-GP 훈련
- 와서스테인 손실 함수를 사용하면 비판자와 생성자의 훈련 균형을 맞출 필요가 없음. => 표준 GAN과 대조적.
- 생성자의 그레디언트가 정확하게 업데이트 되도록 생성자 업데이트 전에 비평자를 훈련하여 수렴. => 생성자가 1번 훈련할 때 비평자가 3번 훈련하는 식.
- 비평자의 손실은 와서스테인 손실과 그레디언트 페널티 가중치의 합.
- 비평자에서는 배치 정규화를 사용하면 안됨. => 배치 정규화는 같은 배치 안의 이미지 사이에 상관 관계를 만들어서 그레디언트 페널티 손실의 효과가 떨어짐. ≒ 그레디언트 클리핑.
4.3.6 WGAN-GP 분석
- 표준 GAN과는 달리 비평자와 생성자의 손실 함수가 매우 안정적 수렴.

4.4 조건부 GAN(CGAN)
- GAN은 생성하려는 이미지의 유형을 제어할 수 없음. => CGAN 사용.
4.4.1 CGAN 구조

- 레이블과 관련된 추가 정보를 생성자와 비평자에게 전달.
- 생성자 : 레이블 정보를 원핫 인코딩된 벡터로 잠재 공간 샘플에 추가.
- 비평자 : 레이블 정보를 RGB 이미지에 추가 채널로 추가. -> 이를 위해 입력 이미지와 동일한 크기가 될 때까지 원핫 인코딩된 벡터를 반복.
- CGAN에서 생성자가 이미지 레이블과 일치하지 않는 완벽한 이미지를 생성하면 비평자는 간단하게 가짜임을 알 수 있음. => 생성자는 제공된 레이블과 출력이 일치하는지 확인.
- 그레디언트 페널티 함수도 원핫 인코딩된 레이블 채널이 필요.
* 데이터셋에 레이블이 있으면 CGAN을 사용 안해도 입력에 레이블을 포함하는 것이 좋음. => 이미지 품질 상승.
* 후에 깨달은 것
- 판별자는 활성화 함수로 시그모이드를 사용.(tanh가 아님!!!)
- CGAN에서 비평자는 레이블 정보를 RGB 이미지에 추가 채널로 추가하고 이를 위해 입력 이미지와 동일한 크기가 될 때까지 원핫 인코딩된 벡터를 반복.
=> 위 말의 뜻 : 만약 특성 레이블의 원핫 인코딩이 1 x 10 크기이고 이미지가 64 x 64이면, 둘의 크기가 맞지 않아 채널로 추가 할 수 없으니까 특성 레이블의 원핫 인코딩이 이미지와 크기가 같아질 때까지 반복햐거 쌓음.
'읽어보기, 교재 > 만들면서 배우는 생성 AI' 카테고리의 다른 글
| CHAPTER 6. 노멀라이징 플로 모델 (0) | 2025.02.23 |
|---|---|
| CHAPTER 5. 자기회귀 모델 (4) | 2025.02.16 |
| CHAPTER 3. 변이형 오토인코더 (6) | 2025.02.14 |
| CHAPTER 2. 딥러닝 (0) | 2025.02.14 |
| CHAPTER 1. 생성 모델링 (2) | 2025.02.14 |