
CHAPTER 3. 변이형 오토인코더
2025. 2. 14. 13:36ㆍ읽어보기, 교재/만들면서 배우는 생성 AI
변이형 오토인코더는 현재 생성 모델링 분야의가장 기본적인 딥러닝 구조.
3.2 오토인코더
- 인코딩 : 네트워크 이미지 같은 고차원 입력 데이터를 저차원 임베딩 벡터로 압축.
- 디코딩 : 네트워크 임베딩 벡터를 원본 도메인으로 압축 해제.(원본 임베딩이 없는 위치에서도 재구성 가능)
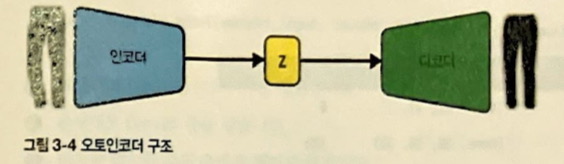
- 오토인코더 : 인코딩, 디코딩 작업을 수행하도록 훈련된 신경망.
3.2.3 인코더
- 입력 이미지를 잠재 공간 안의 임베딩 벡터에 매핑.
- 스트라이드 2를 사용해 각 층에서 출력 크기를 절반 줄이고 채널을 늘려 점진적 고수준 특성 학습.
=> 표준 합성곱 층

3.2.4 디코더
- 전치 합성곱 층(transposed convolutional layer)
- 디코더의 가장 큰 특징.
- 표준 합성곱 층과 원리는 동일하지만 입력 텐서의 높이와 너비를 두배로 늘림.
- Strides 매개 변수가 이미지 픽셀 사이에 추가되는 제로 패딩을 결정.
- 최종적으로 원본 크기 이미지 생성.
3.2.5 인코더와 디코더 연결하기
autoencoder = Model(encoder_input, decoder(encoder_output))
autoencoder.compile(optimizer="adam", loss="binary_crossentropy")- 손실 함수 선택
- RMSE : 생성된 출력이 평균 픽셀 값 중심으로 대칭 분포. -> 큰 값, 작은 값 동일하게 불이익.
- 이진 크로스 엔트로피 : 극단적인 오차가 0.5에 가까운 오차보다 훨씬 큰 손실. -> 실제 픽셀 값에 상관없이 0.5가 기준.
=> 이진 크로스 엔트로피는 흐릿한 이미지, RMSE는 픽셀 격자가 뚜렷한 엣지 생성.
3.2.8 새로운 이미지 생성하기
- 오토인코더가 인코딩을 할 때 2차원 잠재공간에서 연속성을 강제하제 않아 비슷한 포인트가 모인 그룹 사이에 큰 간격 생김.
=> 빈 공간에서 잘 형성된 이미지가 안나옴.
=> 변이현 오토인코더 사용.
3.3 변이형 오토인코더(VAE)
- 핵심 이론
- 벡터에 대한 느슨한 접근 방식으로 국부적 불연속성 문제를 해결.
- 각 아이템 중앙 영역을 가운데 가깝게 위치.
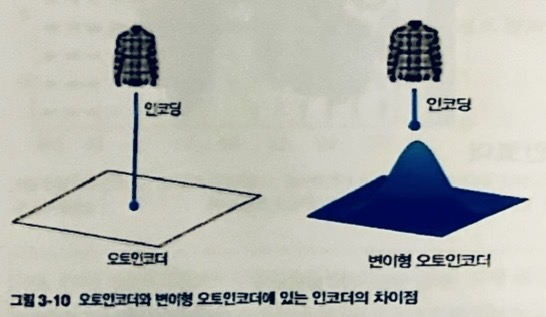
3.3.1 인코더
- 각 이미지가 잠재 공간에 있는 포인트 주변의 다변량 정규 분포에 매핑.
=> 잠재공간에서 차원간 상관관계가 없다가 가정.
* 다변량 정규 분포는 정규 분포 개념을 1차원 이상으로 확장.
- 다변량 정규 분포를 정의하는 2개의 벡터 인코딩.
- z_mean : 이 분포의 평균 벡터.
- z_log_var : 차원별 분산의 로그 값.
z_sigma = exp(z_log_var * 0.5)
epsilon = N(0,1) #랜덤 샘플링을 위한 변수
z = z_mean + z_sigma * epsilon- 디코더는 오토인코더와 동일.
인코더가 z_mean 주변 영역에서 랜덤한 포인트로 샘플링해 연속적 잠재공간이 만들어짐.
- 재매개변수화 트릭(reparameterization trick) : 층의 모든 무작위성을 변수 epsilon에 포함해 층 입력에 대한 출력의 편도 함수를 결정론적(즉, epsilon과 무관)으로 표시할 수 있음. -> 역전파를 위해 필수적.

3.3.2 손실 함수
- 오토인코더는 재구성 손실 함수만 있지만 VAE에는 쿨백-라이블러 발산(KL 발산)을 추가로 사용.
- KL발산 : 한 확률 분포가 다른 분포와 얼마나 다른지.(잠재 공간의 모든 차원에서 수행.)
- 사용이유
- 잠재공간에서 잘 정의된 정규 분포(표준 정규 분포)를 가지게 됨.
- 포인트 군집 사이에 큰 간격이 생길 가능성 적음.
* 가중치가 크면 모델이 압도 당하므로 튜닝 필요.
3.3.4 VAE 분석
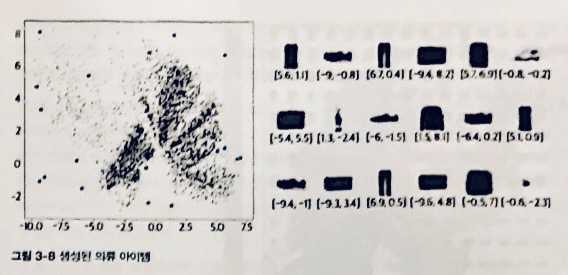

3.4 잠재공간 탐색하기
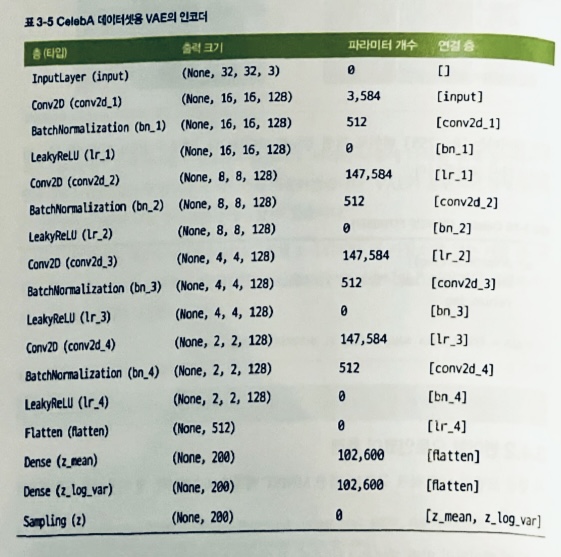
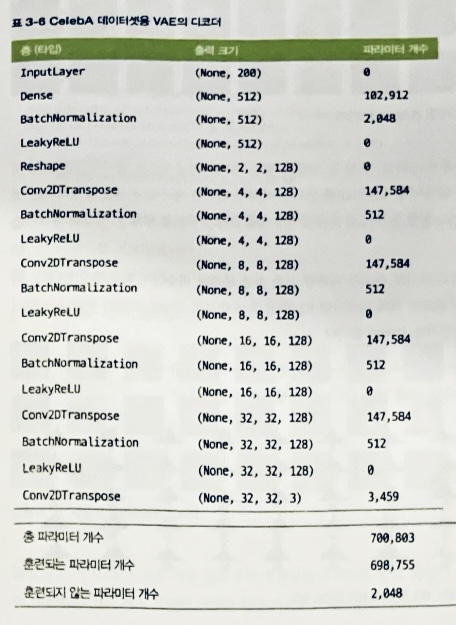
- MNIST 패션 데이터가 아닌 얼굴 데이터(Celeb A)를 사용했을 때 모델 구조 특징.
- 흑백이 아니므로 채널이 3(RGB).
- MNIST는 잠재공간 차원이 2였지만 얼굴은 복잡하므로 차원을 200.
- KL 발산을 위한 β인수는 2,000이지만 튜닝 필요.
3.4.3 VAE 분석
- VAE의 목적은 완벽한 재구성이 아닌 새로운 얼굴 이미지 생성.
=> 잠재 공간의 포인트 분포가 다변량 표준 정규 분포와 비슷한지 확인.

3.4.5 잠재 공간상의 계산
- 예를 들어 슬픈 표정을 미소로 바꾸고 싶을 때
- 잠재 공간에서 미소가 많아지는 방향의 벡터 찾음.
- 이 벡터를 잠재 공간에 있는 원본 이미지의 인코딩에 더함.
* 방향 벡터 : 해당 속성이 있는 이미지가 잠재공간에 인코딩 된 평균 위치에서 해당 속성이 없는 이미지가 인코딩된 평균 위치를 빼면 구할 수 있음.
z_new = z + alpha * feature_vector* alpha 값은 특성 벡터를 얼마나 더할지 결정.
- 마찬가지로 두 얼굴 A, B를 합성하려면
z_new = z_A * (1 - alpha) + z_B * alpha
VAE는 모델의 무작위성을 주입하고 포인트가 잠재공간에 분포되는 방식을 제한함으로써 오토인코더의 문제를 해결.
* 후에 깨달은 것
- 다변량 정규 분포 : 특징을 잠재 공간내에 한 점에 찍는 것이 아닌 분포의 평균 주변 분산내에 위치 시켜 잠재 공간내에 연속성을 늘리는 것.
- 쿨백-라이블러 발산 : 특징의 분포 내 평균을 옮기는 것이 아닌 그 주변 분산을 표준 정규 분포에 가깝게(다른 특징들이 모두 비슷해지게) 바꾸는 것.
=> 표준 정규 분포는 분포의 평균을 중심으로 편향되지 않고 골구로 분포되어 있어 잠재 공간 내 빈 공간이 줄어든다.

728x90
'읽어보기, 교재 > 만들면서 배우는 생성 AI' 카테고리의 다른 글
| CHAPTER 6. 노멀라이징 플로 모델 (0) | 2025.02.23 |
|---|---|
| CHAPTER 5. 자기회귀 모델 (4) | 2025.02.16 |
| CHAPTER 4. 생성적 적대 신경망 (4) | 2025.02.14 |
| CHAPTER 2. 딥러닝 (0) | 2025.02.14 |
| CHAPTER 1. 생성 모델링 (2) | 2025.02.14 |