
2025. 5. 25. 23:23ㆍ연구하기, 지식
서론
TitaNet-L | NVIDIA NGC
TitaNet model for Speaker Verification and Diarization tasks
catalog.ngc.nvidia.com
- NVIDIA NeMo Framework에서는 오디오 관련 다양한 라이브러리를 지원한다. 특히 TitaNet을 기반으로 하는 Speaker Recognition Pretrained Model은 성능이 매우 우수 하다. 더욱이 별다른 파인튜닝 작업을 거치지 않아도 좋은 성능을 자랑 한다.

- 필자도 몇 번 학습을 진행했으나 유의미한 효과는 얻지 못했다. 하지만 모델을 도와줄 수 있는 알고리즘을 만들어 성능을 높일 수 있지 않을까? 전에 봤던 논문에서 아이디어를 얻어 적용해보려고 한다.
- 파인튜닝 법 : https://meerkat-developer.tistory.com/6
NeMo speaker embedding model(TitaNet-L) FInetuning 코드
2025.02.03 - [R&D] - NeMo speaker embedding model(TitaNet-L) 학습 코드 NeMo speaker embedding model(TitaNet-L) 학습 코드공식문서에는 jupyter notebook 기준으로 나와 있지만 py 환경에 맞게 재구성.각종 명령어들은 subproces
meerkat-developer.tistory.com
기초 아이디어
https://meerkat-developer.tistory.com/22
U-Net: Convolutional Networks for BiomedicalImage Segmentation(18 May 2015)
* 원문 논문 아카이브https://arxiv.org/abs/1505.04597 U-Net: Convolutional Networks for Biomedical Image SegmentationThere is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper,
meerkat-developer.tistory.com
- 전에, U-Net 논문을 읽은 적이 있었다. 해당 논문에서 '오버랩 타일 전략' 부분에서 이미지 경계면에서 미러링을 사용한다. 쉽게 말해 끝 부분은 이미지가 잘리니 반전 시켜서 이어 붙여 제로 패딩 같은걸 하지 않는다. 만약 제한 적인 오디오가 들어와 speaker recognition을 해야할 때 성능은 떨어질 것이다. 이 때, 미러링 처럼 오디오를 반전시켜 이어붙이면 성능이 늘어나지 않을까?
실험1(오디오 이어 붙이기)
- 조건은 이렇다. 두 화자가 대화를하고 해당 오디오를 1.5초 씩 청킹을 해 저장 해놓는다. 그리고 한 명의 화자에 대해서만 25초 분량의 음원을 새로 녹음해 NeMo Pretrained Model을 사용해 embedding을 따 놓는다. 그 후 저장해놓은 청킹 오디오의 embedding을 따 코사인 유사도의 평균을 구한다. 추가 녹음한 화자의 코사인 유사도 평균과 녹음하지 않은 화자의 유사도 평균의 차가 크면 클 수록 더욱 구분을 잘하는 것이다.
- 기본 유사도 평균 구하는 코드
import os
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.spatial.distance import cosine
def folder_embedding_analysis(folder1, folder2, ref_embedding):
base_dir = "/content/drive/MyDrive/treat_audio/split_segments"
target_dirs = {
folder1: os.path.join(base_dir, folder1),
folder2: os.path.join(base_dir, folder2)
}
def cosine_similarity(a, b):
return 1 - cosine(a, b)
ref_embedding = ref_embedding.cpu().numpy().flatten()
all_results = {}
for label, folder in target_dirs.items():
similarities = []
for filename in os.listdir(folder):
if filename.endswith(".wav"):
file_path = os.path.join(folder, filename)
emb = speaker_model.get_embedding(file_path)
emb = emb.cpu().numpy().flatten()
sim = cosine_similarity(ref_embedding, emb)
similarities.append(sim)
similarities = np.array(similarities)
all_results[label] = similarities
print(f"\n[{label}] 유사도 통계:")
print(f"- 평균: {similarities.mean():.4f}")
print(f"- 표준편차: {similarities.std():.4f}")
print(f"- 최댓값: {similarities.max():.4f}")
print(f"- 최솟값: {similarities.min():.4f}")- 아무런 처리를 하지 않은 유사도 평균 차이 : 0.2349
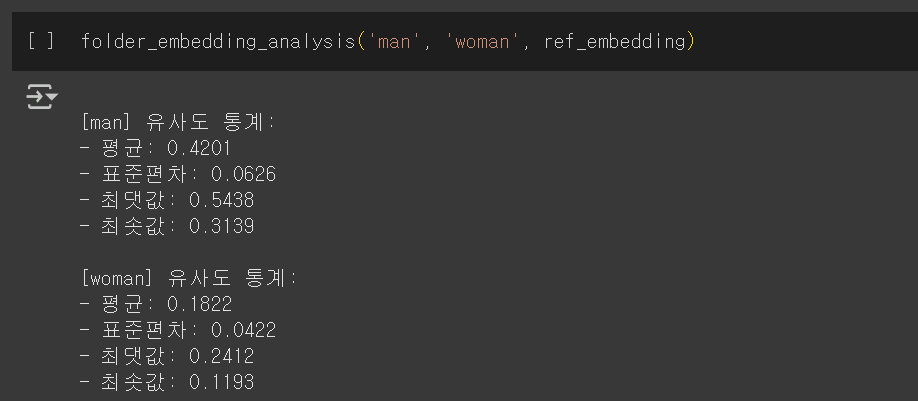
- 반전 시킨 오디오를 이어붙인 유사도 평균 차이 : 0.1792

* 오디오 반전법 : https://meerkat-developer.tistory.com/29
파이썬에서 오디오 파일 다루기(pydub, soundfile)
서론 파이썬에는 다양한 오디오 관련 라이브러리가 있다. 필자는 주로 pydub 라이브러리를 사용한다. 사용하기 간편하고 Numpy 배열로 오디오를 불러오는 방식이 아니어서 조금 더 직관적이기 때
meerkat-developer.tistory.com
1차 결론
- 망했다. 성능이 더 안좋아 졌다. 아무래도 이미지와 오디오는 데이터 특성이 다르니 그런 것 같다. 이를 테면, 한국어 오디오를 반전 시켜 버리면 기존 화자의 오디오 특징들은 무시되고 독일어 마냥 말한다. 기분이 좋지 않다. 독일어 하니까 쿠엔틴 타란티노 감독의 '바스타즈 거친 녀석들' 이나 보고 싶다. 하지만 여기서 멈추면 안된다.
실험2(임베딩 수정하기)
- NeMo 모델은 오디오의 임베딩을 만드는 것이다. 코사인 유사도는 임베딩 사이의 유사도를 측정하는 것이다. 그렇다면 임베딩에 직접 적인 변화를 주면 되지 않을까? 임베딩 증강 기법을 사용해 특징을 더욱 강건하게 해보겠다. 스케일, 노이즈 추가, 드롭 아웃을 임베딩에 적용해 평균 차이를 더욱 크게 해보겠다. 1.5초 음성에 대해서만 임베딩 증강을 적용하고, 파라미터들을 조합해 최고의 조합을 찾아낸다.
import os
import numpy as np
import torch
from scipy.spatial.distance import cosine
from itertools import product
# 1. 임베딩 증강 함수
def augment_embedding(embedding, scale=1.5, noise_std=0.01, dropout_prob=0.1):
with torch.no_grad():
emb_norm = embedding / embedding.norm(p=2)
emb_scaled = emb_norm * scale
noise = torch.randn_like(embedding) * noise_std
emb_noisy = emb_scaled + noise
dropout_mask = (torch.rand_like(embedding) > dropout_prob).float()
emb_dropped = emb_noisy * dropout_mask
return emb_dropped
# 2. 코사인 유사도 계산
def cosine_similarity(a, b):
return 1 - cosine(a, b)
# 3. 파라미터 조합별 성능 평가
def evaluate_parameter_combinations(folder1, folder2, ref_embedding):
base_dir = "/content/drive/MyDrive/treat_audio/split_segments"
target_dirs = {
folder1: os.path.join(base_dir, folder1),
folder2: os.path.join(base_dir, folder2)
}
# 파라미터 범위 설정
scales = [1.0, 1.2, 1.5, 1.8, 2.0]
noise_stds = [0.0, 0.005, 0.01, 0.02]
dropouts = [0.0, 0.1, 0.2, 0.3]
ref_embedding = ref_embedding.to("cuda")
best_config = None
max_diff = -1
results = []
# 모든 파라미터 조합 반복
for scale, noise, dropout in product(scales, noise_stds, dropouts):
folder_means = {}
for label, folder in target_dirs.items():
similarities = []
for filename in os.listdir(folder):
if filename.endswith(".wav"):
file_path = os.path.join(folder, filename)
emb = speaker_model.get_embedding(file_path).to("cuda")
# 임베딩 증강
emb_aug = augment_embedding(emb, scale, noise, dropout)
# ref_aug = augment_embedding(ref_embedding, scale, noise, dropout)
sim = cosine_similarity(
ref_embedding.cpu().numpy().flatten(),
emb_aug.cpu().numpy().flatten()
)
similarities.append(sim)
folder_means[label] = np.mean(similarities)
# 평균 차이 계산
diff = abs(folder_means[folder1] - folder_means[folder2])
results.append({
'scale': scale,
'noise_std': noise,
'dropout_prob': dropout,
'mean_diff': diff,
'folder1_mean': folder_means[folder1],
'folder2_mean': folder_means[folder2]
})
if diff > max_diff:
max_diff = diff
best_config = results[-1]
# 결과 출력
print("가장 큰 평균 유사도 차이를 낸 조합:")
print(best_config)
return best_config, results2차 결론
- 최고 조합 : {'scale': 1.2, 'noise_std': 0.005, 'dropout_prob': 0.1, 'mean_diff': 0.24496975606676727, 'folder1_mean': 0.4032348251247038, 'folder2_mean': 0.15826506905793655}
- 유사도 평균 차이 : 0.2450
- 기본 0.2349에서 약 4% 향상된 0.2450의 결과가 나왔다. 놀랍다. 임베딩만 만져줘도 더욱 확실하게 분리할 수 있어졌다. 이렇다면 멈출수 없다. 파라미터들을 더 늘려봐 조합을 찾아야겠다.
실험3(최고의 파라미터 조합 찾기)
- 우리 모두 머신러닝 공부할 때 XGBoost 모델을 사용해보았다. 해당 모델을 사용할 때 파라미터 튜닝이 어렵기 때문에 그리드서치라는 기법을 사용한다. 파라미터들의 최고의 조합을 찾는 방법이다. 나도 이 아이디어를 적용해보려고한다. 파라미터 범위를 설정해 그 중에서 랜덤 샘플링을 통해 최고의 파라미터 조합을 찾아 보겠다.
import os
import numpy as np
import torch
import random
from scipy.spatial.distance import cosine
from itertools import product
# 1. 임베딩 증강 함수
def augment_embedding(embedding, scale=1.5, noise_std=0.01, dropout_prob=0.1):
with torch.no_grad():
emb_norm = embedding / embedding.norm(p=2)
emb_scaled = emb_norm * scale
noise = torch.randn_like(embedding) * noise_std
emb_noisy = emb_scaled + noise
dropout_mask = (torch.rand_like(embedding) > dropout_prob).float()
emb_dropped = emb_noisy * dropout_mask
return emb_dropped
# 2. 코사인 유사도 계산
def cosine_similarity(a, b):
return 1 - cosine(a, b)
# 3. 파라미터 조합별 성능 평가
def evaluate_parameter_combinations(folder1, folder2, ref_embedding, num_samples=1000):
base_dir = "/content/drive/MyDrive/treat_audio/split_segments"
target_dirs = {
folder1: os.path.join(base_dir, folder1),
folder2: os.path.join(base_dir, folder2)
}
# 더 넓은 파라미터 범위
scales = np.round(np.linspace(0.8, 2.5, 10), 2).tolist()
noise_stds = np.round(np.linspace(0.0, 0.05, 11), 3).tolist()
dropouts = np.round(np.linspace(0.0, 0.5, 11), 2).tolist()
all_param_combinations = list(product(scales, noise_stds, dropouts))
# 무작위 샘플링
sampled_combinations = random.sample(all_param_combinations, min(num_samples, len(all_param_combinations)))
ref_embedding = ref_embedding.to("cuda")
best_config = None
max_diff = -1
results = []
for scale, noise, dropout in sampled_combinations:
folder_means = {}
for label, folder in target_dirs.items():
similarities = []
for filename in os.listdir(folder):
if filename.endswith(".wav"):
file_path = os.path.join(folder, filename)
emb = speaker_model.get_embedding(file_path).to("cuda")
emb_aug = augment_embedding(emb, scale, noise, dropout)
sim = cosine_similarity(
ref_embedding.cpu().numpy().flatten(),
emb_aug.cpu().numpy().flatten()
)
similarities.append(sim)
folder_means[label] = np.mean(similarities)
diff = abs(folder_means[folder1] - folder_means[folder2])
results.append({
'scale': scale,
'noise_std': noise,
'dropout_prob': dropout,
'mean_diff': diff,
'folder1_mean': folder_means[folder1],
'folder2_mean': folder_means[folder2]
})
if diff > max_diff:
max_diff = diff
best_config = results[-1]
print("가장 큰 평균 유사도 차이를 낸 조합:")
print(best_config)
return best_config, results3차 결론
- 최고 조합 : {'scale': 1.93, 'noise_std': 0.05, 'dropout_prob': 0.1, 'mean_diff': 0.25053386198762095, 'folder1_mean': 0.3907382514966554, 'folder2_mean': 0.14020438950903444}
- 유사도 평균 차이 : 0.2505
- 기본 0.2349에서 약 6% 향상된 성능이다. 별 다른 학습 없이도 Pretrained Model의 성능을 올렸다. 이래서 다양한 논문들을 읽고 다양한 모델들을 접해봐야 한다. 이 기술을 좀 더 방대한 데이터에 적용해 일반화 성능 향상으로 이어질지 테스트 해봐야겠다.
'연구하기, 지식' 카테고리의 다른 글
| JIT 컴파일과 데코레이터 (2) | 2025.06.09 |
|---|---|
| 푸리에 변환(Fourier transform, FT) (2) | 2025.06.02 |
| 파이썬에서 오디오 파일 다루기(pydub, soundfile) (0) | 2025.05.25 |
| API 통신과 소켓 통신 (4) | 2025.05.18 |
| 쿨백-라이블러 발산(Kullback–Leibler divergence, KLD) (1) | 2025.05.06 |